Off-Topic
Git LFS for Dummies
14. November 2019
Versionsverwaltungssysteme wie Git kennt und nutzt (hoffentlich) jeder Entwickler. Was aber, wenn die Daten einmal nicht textbasiert vorliegen; wenn Multimedia Assets auch eingecheckt werden sollen? Eine Todsünde?
In Git we trust
Verteilte Versionsverwaltungssysteme wie Git sind im Alltag eines Programmierers nicht wegzudenken. Wer es nicht schon verwendet, sollte es spätestens vorgestern tun. Ansonsten schicken wir dir Linus Torvalds, den ursprünglichen Entwickler von Git und dem Linux Kernel, und damit generell Koryphäe in der Software-Szene vorbei. Und das willst du nicht. Denn gegen manche Menschen will man nicht argumentieren müssen.
Aber was ist dieses Git nun eigentlich?
Hier ein kurze Einführung. Git erstellt für jede Version einer Datei, die du beschließt “aktiv abzuspeichern” einen Snapshot, auf den man später referenzieren kann (= ein Commit). Diese Sammlung aller Dateien, in allen älteren bis hin zur aktuellen Version nennt sich Repository oder kurz Repo. Jeder Entwickler, der an einem Projekt mitarbeiten will, muss sich eine Instanz dieses Repos lokal auf seinen Rechner klonen (= working copy). Dann kann man dann damit auch in alle jemals passierten Änderungen einsehen, ohne dafür dauerhaft mit dem Server (= remote) verbunden zu sein. Nebenbei bemerkt kann man Git auch nur lokal ohne einen Server verwenden, wenn man Dateien nur für sich selbst in gleicher Weise versionieren will.
Wenn lokal Änderungen in Dateien passieren, protokolliert Git diese mit. Will man einen neuen Stand seiner Arbeit sichern, fängt man an sie für einen commit vorzumerken (= stage). Als Best-Practice sollte man dabei mit Git nur textbasierte Dateien versionieren. In welchen Änderungen und Unterschiede zwischen altem und neuen Stand effizient (bzw. überhaupt in einer sinnvollen Weise) ermittelt werden können. Hat man alle gewünschten Änderungen an seinen Files vorgenommen und sie gestaged, gibt man eine noch commit message ein, die kurz und knackig beschreibt welche (und bestenfalls auch warum) Änderungen vorgenommen wurden. Dann kann man den commit zu seiner working copy hinzufügen. Wenn man seinen commit dann noch mit anderen Entwicklern teilen will, muss man schlussendlich die Änderungen noch auf den zentralen Server schieben (= pushen).
Soviel zu einem schnellen Überblick. Aber wer schon einmal von Git gehört hat, ist mit alledem hoffentlich bestens vertraut.
Textbasierte Dateien vs. binäre Blobs
Was aber wenn man Dateien versionieren soll, die nicht textbasiert sind?
Sieht man sich aber in einer Sparte wie der unseren oder im Bereich der Spieleentwicklung um, kommt es häufig vor, dass z. B. auch diverse Assets mit in ein Repository eingecheckt werden sollen. Assets können Vieles sein, hier ein paar Beispiele:
-
ein 3D Modell
-
eine Textur, die auf ein Modell gelegt wird
-
eine Audio oder Videodatei, die in einer App später abgespielt werden sollen
Diese Arten von Dateien sind (größtenteils) nicht textbasiert und somit ist es auch nicht (leicht bzw. überhaupt sinnvoll) möglich, die genauen Änderungen innerhalb von Dateien zu erkennen und zu merken. Dinge, wie Kompressionsalgorithmen in Bildern, Videos oder auch oft 3D-Assets, verschlechtern bzw. verhindern die Möglichkeit einer solchen Unterschieds-Erkennung. Was grundsätzlich ja eine super Idee ist, um enorm viel Speicherplatz einzusparen. Das heißt im Weiteren soviel wie: Wenn ich z. B. ein Bild oder 3D-Modell geändert habe und dieses für einen commit vormerke, wird die gesamte Datei als neue Version seiner selbst erneut abgespeichert und nicht nur die Änderungen gemerkt.
Ein kleines Beispiel dazu, welches auch im folgenden Video verwendet wird, für alle Interessierten:
-
Man hat ein großes, buntes Bild, das man gerne versionieren würde. Wir nehmen an es hat 50 MB, denn es ist auch ein sehr großes, sehr buntes und sehr schönes Bild.
-
Danach legt man ein Git Repository an, in das man nur das eine Bild eincheckt, da man nicht mehr Bilder hat, aber gerne auf jede Version des schönen, bunten Bildes später einfach wieder zugreifen können möchte.
-
Man committet die erste Version des bunten Bildes. Somit hat das repository initial eine Größe von 50 MB.
-
Nach einiger Zeit hat man Änderungen an das schöne bunte Bild vorgenommen und findet, es ist wieder soweit, man meißelt die Änderungen in den sprichwörtlichen Stein, hier in Wahrheit die git history. (Wer mehr über DAGs wissen möchte, die dahinter stecken, der ist mir zwar sympathisch, leider aber gerade beim falschen Artikel ? Trotzdem fleißig weiterlesen).
-
Man committet die neue Version des Bildes, die zufällig auch wieder 50 MB hat. Wir erinnern uns daran, was wir vorher über nicht-textbasierte Dateiformate gelernt haben. Das weiters bedeutet, dass man das neue bunte Bild quasi als neues File behandelt. In dem sich quasi alles geändert hat. Das Repo hat somit eine Größe von 100 MB.
-
Weil man so fleißig war, und Tag und Nacht an seinem Meisterwerk gearbeitet hat, folgt kurze Zeit später auch schon die nächste Änderung in seinem Bild. Also das selbe Spiel wie zuvor. Und zack: Das Repo hat plötzlich 150 MB und das nach erst drei commits.
Ich denke, es ist ersichtlich, wo das Beispiel hinführt, wenn man in einer realen Umgebung viele unterschiedliche, solcher nicht-textbasierten Assets hat, die sich häufig ändern. Wenn jemand das Repository klont, würden dann im Endeffekt alle Versionen eines jeden Files heruntergeladen und abgespeichert werden, da alle im Repo enthalten sind.
Das ist der Punkt an dem Git LFS sein Können unter Beweis stellen kann, aber ich greife voraus.
Git LFS — save all the files
Das “LFS” steht für “large file storage” und lässt schon auf den Verwendungszweck schließen. Git LFS ist FOSS und wurde als Erweiterung zu Git in Kooperation von Atlassian, GitHub und vielen weiteren Kontributoren entwickelt. Es soll in Szenarien wie dem genannten Beispiel Anwendung finden.
Um Git LFS in seinem Repository zu aktivieren, muss man es installieren und um den Rest kümmert sich Git. Ganz grob gesagt: Der Hoster des Repos muss es auch unterstützen, was BitBucket, GitHub sowie GitLab alle tun, um ein paar bekannte Beispiele zu nennen.
Man kann also nun beginnen die Dateien zu definieren, die automatisch in Git LFS aufgenommen werden sollen. Dabei kann man einzelne Dateien und Ordner definieren, für die sich Git LFS verantwortlich fühlen soll. Oder man stellt einen Filter z. B. nach Dateiendung ein.
Git LFS track & .gitattributes
Will man beispielsweise einen Filter für das gängige Bildformat JPG einstellen, kann man dies mit dem folgenden Befehl bewerkstelligen. Die doppelten Hochkomma sind dabei relevant, außer man möchte nur alle derzeit in der working copy befindlichen .JPG Dateien zu Git LFS hinzufügen. Aber keine künftigen, daher: Schau genau und denke darüber nach was du möchtest.
git lfs track „*.jpg“
Dadurch wird im Basisverzeichnis des Repositories eine Datei mit dem Namen .gitattributes angelegt. In der man alle zu filternden Files und weitere optionale Dinge spezifizieren kann. Mit dem einen Filter sieht diese Datei dann folgendermaßen aus:
*.jpg filter=lfs diff=lfs merge=lfs -text
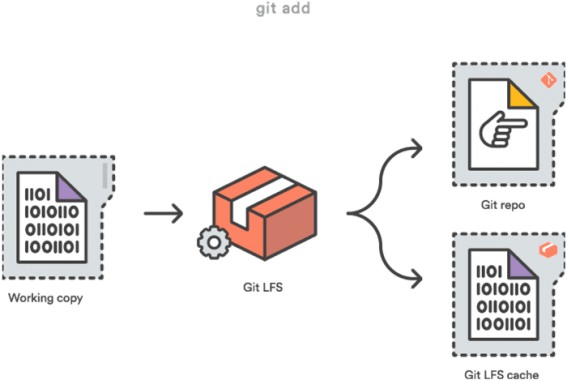
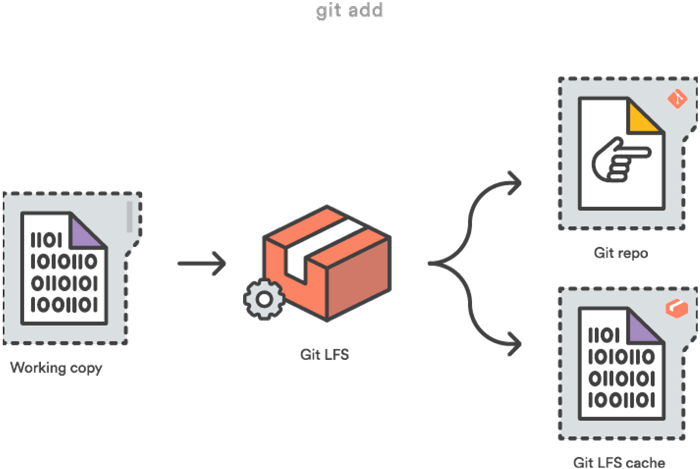
Fügt man nun eine neue Datei zum Repo hinzu, auf die eines der angegebenen Attribute zutrifft, wird es ohne zutun des Users von Git transparent durch eine Zeiger-Datei ersetzt, die auf den eigentlichen Inhalt verweist. Dieser Inhalt liegt dann aber in einem gesonderten Bereich, dem LFS cache — zu sehen in der folgenden Abbildung.
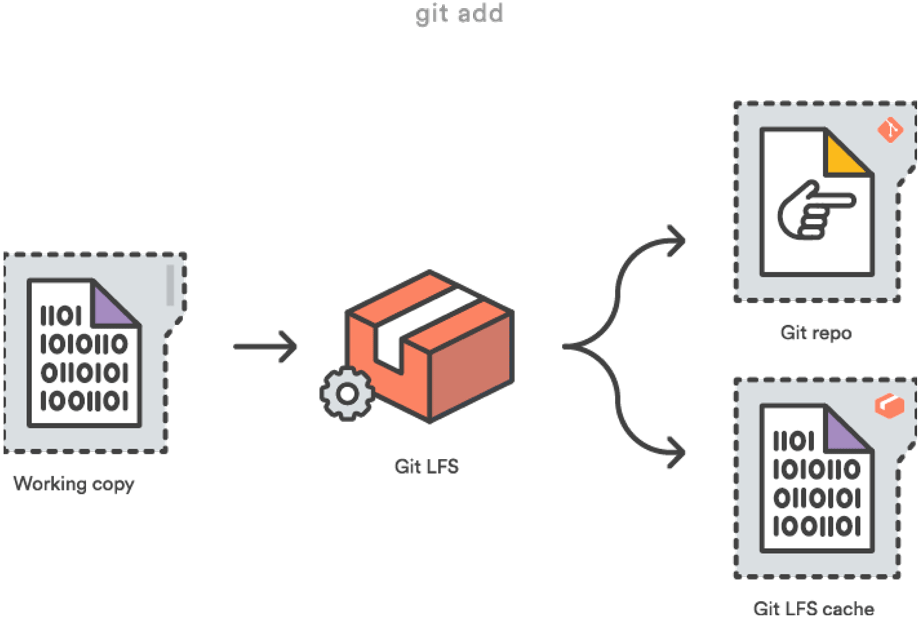
Wenn man seine Änderungen nun lokal zu seiner working copy hinzufügt, um sie danach zum Server zu pushen, werden alle Dateien, die in Git LFS referenziert sind, von dem lokalen LFS cache auf den LFS store am Server übertragen.
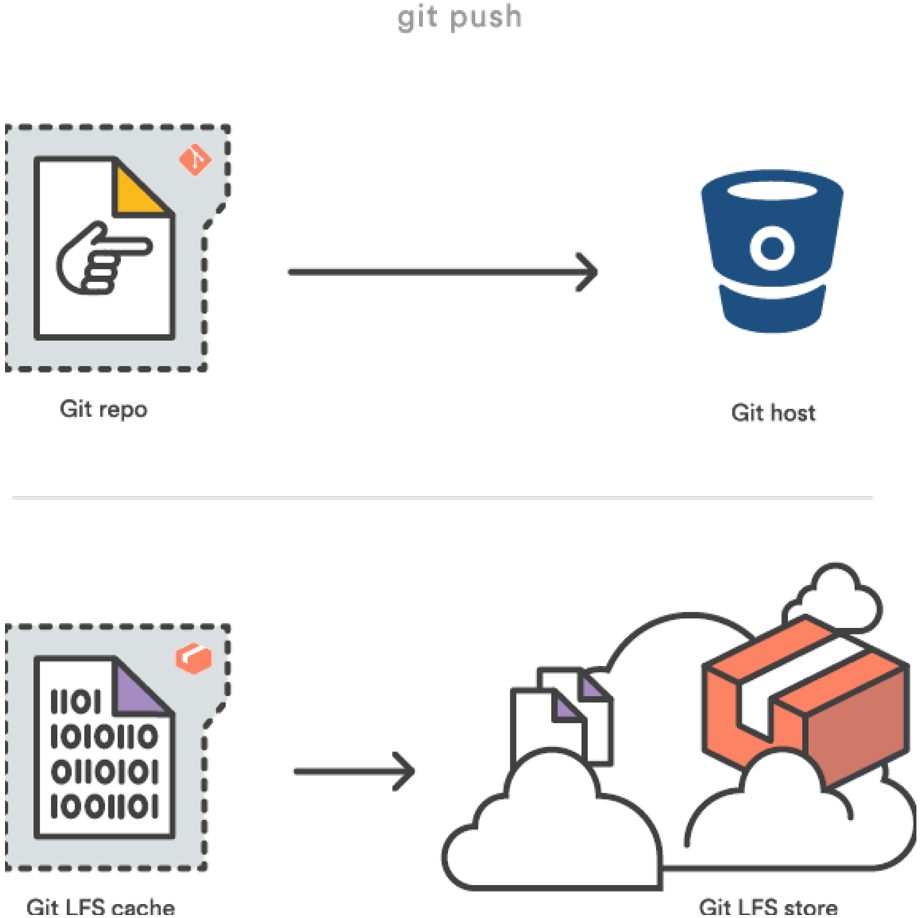
Auf Seite des Entwicklers ändert sich dabei am Workflow nur, dass man einmalig alle gewünschten Dateien spezifizieren muss. Keine zusätzlichen Kommandos. Nur ein riesiger Vorteil, zu dem wir jetzt kommen.
Der eigentliche Vorteil
Angenommen ich habe ein Projekt an dem schon lange aktiv gearbeitet wird und das schon tausenden commits hat. Ich weiß auch, dass es beispielsweise viele 3D Modelle und ein paar Audiodateien enthält, die sich über die Zeit der Entwicklung laufend verändert haben. Es stellen sich mir die Nackenhaare auf, sollte in diesem Repository noch kein Git LFS aktiviert sein und ein neuer Mitarbeiter müsste sich das Repo klonen.
Würde er dies tun, so würde standardmäßig jeder Snapshot eines jeden Files, der über die Zeit committed wurde, im Hintergrund von git heruntergeladen und lokal gespeichert werden. Ich höre unser aller Festplatten, die ohnehin schon immer übergehen, leise in der Ferne weinen, wenn ich nur daran denke.
Doch hier kommt der Clue — die Rettung naht!
In Form von Git LFS. Denn wenn man nun das Repo klont bzw. einen commit auscheckt, der Git LFS Zeiger enthält, dann werden diese vollautomatisch von Git im Hintergrund aus dem remote LFS store heruntergeladen. Falls sie nicht sogar schon in meinem lokalen LFS cache liegen. Der entscheidende Punkt dabei ist, dass nur die neuesten Versionen der Files im LFS geholt werden, ansonsten wäre das Ganze erst wieder für die Katz.
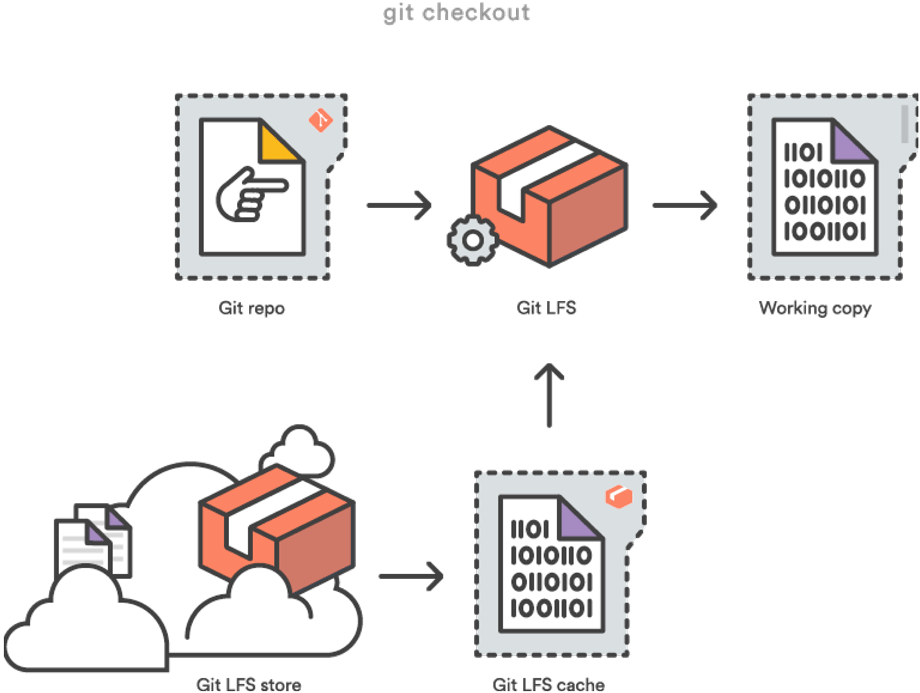
Git LFS entscheidet dabei vollautomatisch welche Dateien von aktuelle ausgecheckten commits benötigt werden und holt auch nur diese. Natürlich kann ich dieses Verhalten auch nach seinem Belieben anpassen. Möchte man beispielsweise mehr als nur die erwähnten letzten Versionen der LFS Dateien, so kann man dies mit dem folgenden Kommando machen:
git lfs fetch –recent
Git kümmert sich in beiden Fällen wiederum um alles im Hintergrund und man merkt als Anwender davon nichts, außer die Ersparnisse in Sachen Speicherplatz. Coole Sache!
prune — noch mehr Sparen geht nicht
Ein letzter Tweak für alle, die sich sicher sind, dass da noch mehr geht. Dem stimme ich zu, darum noch ein Schmankerl für alle, die es soweit geschafft haben. Diese Ausdauer gehört belohnt: Mit mehr Speicherplatz. Und den gibt es folgendermaßen:
git lfs prune –verify-remote
Wer sich weigert, einen Befehl aus einem Blogpost im Internet einfach so und ohne Erklärung auszuführen, dem sei gesagt: Richtig so! Darum meine Erklärung, was du da eigentlich tust.
Angenommen du arbeitest lange an einem Projekt, in dem Git LFS aktiviert ist. Dann kann es mit der Zeit passieren, dass sich der lokale LFS cache füllt. Oder wenn du eventuell das fetch Kommando von vorhin mit dem –recent flag ausgeführt hast. Dafür ist das pruning gedacht. Es kümmert sich automatisch darum, alle “alten” und ungenutzten Objekten aus dem Cache zu löschen. Was für uns wiederum heißt: Mehr Speicherplatz!
Mit dem flag –verify-remote kann man zusätzlich noch überprüfen, ob die lokal zu löschenden Objekte schon auf dem Server vorhanden sind, ansonsten werden sie an Ort und Stelle im Cache belassen. Dann kann eigentlich nichts mehr schief gehen.
In diesem Sinne: Viel Spaß beim Ausprobieren und vielleicht denkst du ja in Zukunft kurz an diesen Blogpost, wenn du ein neues Repo anlegst und ob es nicht sinnvoll wäre LFS zu aktivieren.
Git happens!







Über den Autor
Felix Gruber